
Goal:
This article digs into Unified Memory Manager which is the default memory management framework for Spark after 1.6.
We will explain why there is a little difference in executor memory size between Spark UI and Executor log.
Env:
Spark 2.4
Concept:
Before Spark 1.6, the legacy memory management framework is Static Memory Manager, which can be turned on by setting "spark.memory.useLegacyMode" to true.
As per the reference post shared, the current architecture of in-heap memory for Unified Memory Manager is as below graph:
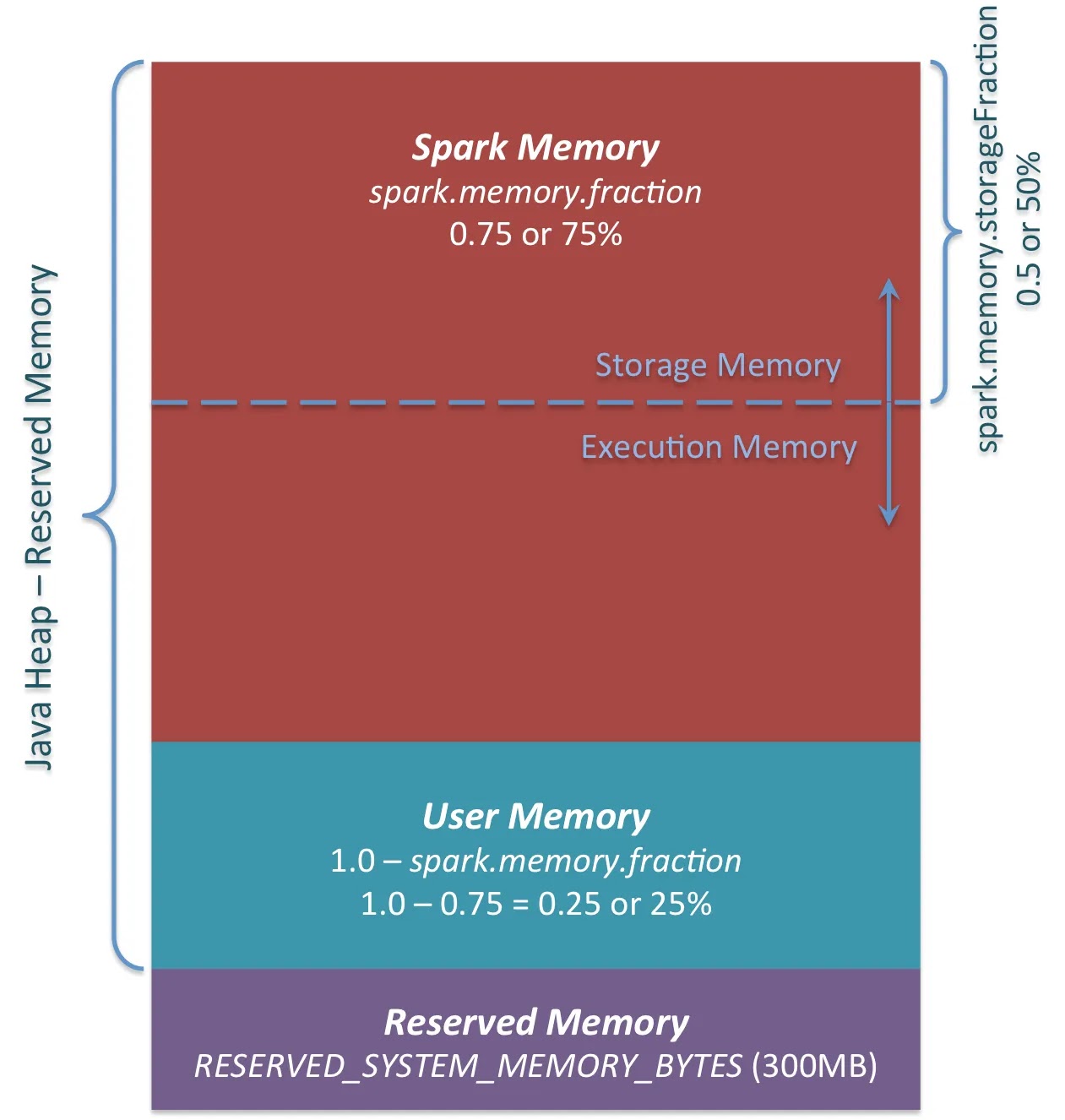
- Note: above graph showed the spark.memory.fraction=0.75 but it has been reduced to 0.6 starting from Spark 2.0 as per SPARK-15796.
Above graph only shows on-heap(aka in-heap) memory, starting from Spark 1.6, it introduced off-heap(aka out-of-heap) memory which can avoid frequent GC, but the tradeoff is it has to deal with memory allocation and release logic. Below 2 parameters are related to:
- spark.memory.offHeap.enabled
- spark.memory.offHeap.size
Graph from this post explains off-heap memory:

In this post we will mainly talk about on-heap memory.
- Note: we will not talk about yarn overhead memory which was shared in other post: Resource allocation configurations for Spark on Yarn. It explains the question why you will get a 5G YARN container even if you only requested a 4G executor.
1. Total java heap size(systemMemory)
The whole of what above graph shows is called "systemMemory" in the source code of Unified Memory Manager.
For example, if you specify "--executor-memory 4G" which defines "--Xmx" of the JVM, "systemMemory" will be a little bit smaller than 4G. It is Runtime.getRuntime.maxMemory:
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)Why Runtime.getRuntime.maxMemory is a little bit smaller than -Xmx? This discussion answers that: "The difference appears to be accounted for by the size of the garbage collector's survivor space.".
We can easily figure out systemMemory in spark-shell(or any scala shell):
spark-shell --master local --deploy-mode client --driver-memory 4G
scala> Runtime.getRuntime.maxMemory
res0: Long = 3817865216
So it means a "-Xmx 4G" executor has systemMemory=3817865216 bytes, which is around 88.9% of "--Xmx".
Though it is not a huge difference, it can help us understand how to calculate Spark UI's "Storage Memory".
1.1 Reserved Memory(reservedMemory)
This is hard-coded as 300MB which is controlled by parameter spark.testing.reservedMemory but it is not recommended to change it. Basically this area is not used by Spark and the usable memory is:
val usableMemory = systemMemory - reservedMemory
1.2 User Memory
Size is (1.0 - spark.memory.fraction) * usableMemory.
By default it is 0.4 * (systemMemory - 300MB).
As per Doc, it is reserved for user data structures, internal metadata in Spark, and safeguarding against OOM errors in the case of sparse and unusually large records.
1.3 Spark Memory
Size is spark.memory.fraction * usableMemory as per the code of function "getMaxMemory":
(usableMemory * memoryFraction).toLong
By default it is 0.6 * (systemMemory - 300MB).
The whole pool is divided into 2 regions(or pools) -- Storage Memory and Execution Memory.
The boundary is controlled by parameter -- spark.memory.storageFraction(default 0.5).
However the beauty is the boundary is dynamic which means, one region/pool can borrow space from the other.
Below graph is from this slides:

1.3.1 Storage Memory
Size is spark.memory.fraction * usableMemory * spark.memory.storageFraction.
By default it is 0.3 * (systemMemory - 300MB).
It is used to store cached blocks immune to being evicted by execution. Eg. cached RDD, broadcast variable, unroll data. This pool support spilling to disk if memory is not enough.
1.3.2 Execution Memory
Size is spark.memory.fraction * usableMemory * (1 - spark.memory.storageFraction).
By default it is 0.3 * (systemMemory - 300MB).
It is used to store objects required during the execution of Spark tasks. Eg. shuffle intermediate buffer on the Map side in memory, hash table for hash aggregation. This pool support spilling to disk but can not be forcefully evicted by other threads (tasks).
2. Spark UI's "Storage Memory"
What is "Storage Memory" shown in Spark UI?
It is actually above "1.3 Spark Memory" in 1000(instead of 1024) units of conversion:
"1.3.1 Storage Memory" + "1.3.2 Execution Memory"
So the Spark UI's "Storage Memory" is a little bit confusing, because it is not only "1.3.1 Storage Memory".
For example, if executor is 4G, Spark UI's "Storage Memory" is show as 2.1GB:

The calculation is:
(3817865216-300*1024*1024)*0.6/1000/1000/1000=2.1019 (GB)
3. Executor log's "MemoryStore started with capacity..."
What is "MemoryStore: MemoryStore started with capacity 2004.6 MB" in executor log:
It is actually above "1.3 Spark Memory" in 1024(instead of 1000) units of conversion:
The calculation is:
(3817865216-300*1024*1024)*0.6/1024/1024=2004.6000 (MB)
Now we know the reasons why different components shows a little bit different number for the same concept between above #1.3, #2 and #3.
4. Task Memory Allocation inside one Executor
Multiple Tasks can run inside one Executor concurrently. How does the memory allocation inside a single Executor?
This logic is explained in ExecutionMemoryPool.scala for method "acquireMemory":
/**
* Try to acquire up to `numBytes` of memory for the given task and return the number of bytes
* obtained, or 0 if none can be allocated.
*
* This call may block until there is enough free memory in some situations, to make sure each
* task has a chance to ramp up to at least 1 / 2N of the total memory pool (where N is the # of
* active tasks) before it is forced to spill. This can happen if the number of tasks increase
* but an older task had a lot of memory already.
*
* @param numBytes number of bytes to acquire
* @param taskAttemptId the task attempt acquiring memory
* @param maybeGrowPool a callback that potentially grows the size of this pool. It takes in
* one parameter (Long) that represents the desired amount of memory by
* which this pool should be expanded.
* @param computeMaxPoolSize a callback that returns the maximum allowable size of this pool
* at this given moment. This is not a field because the max pool
* size is variable in certain cases. For instance, in unified
* memory management, the execution pool can be expanded by evicting
* cached blocks, thereby shrinking the storage pool.
*
* @return the number of bytes granted to the task.
*/
private[memory] def acquireMemory(
In simple, each task will try to get 1/N ~ 1/2N of the total pool size where N is the number of active tasks:
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
So if there is only 1 task running inside that executor, it can use the whole of memory pool.
It can handle straggler tasks better than static way.
Below graph from this slides explains pretty well:



Test:
import org.apache.spark.storage.StorageLevel
val parquetFileDF = spark.read.parquet("/tpcds/store_sales").coalesce(2)
parquetFileDF.persist(StorageLevel.MEMORY_ONLY)
INFO MemoryStore: Block rdd_33_0 stored as values in memory (estimated size 1447.7 MB, free 556.1 MB)


Reference:
https://0x0fff.com/spark-memory-management/
https://developpaper.com/spark-unified-memory-management/
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/memory/UnifiedMemoryManager.scala
https://spark.apache.org/docs/3.0.0/configuration.html#memory-management
https://bjlovegithub.gitbooks.io/learning-apache-spark/content/how-is-memory-managed-in-spark.html
http://www.wdong.org/spark-on-yarn-where-have-all-the-memory-gone.html
https://www.tutorialdocs.com/article/spark-memory-management.html
https://www.slideshare.net/databricks/deep-dive-memory-management-in-apache-spark
https://programmersought.com/article/72405407802/
No comments:
Post a Comment